






Обзор CuneiForm: возможности OCR, точность распознавания, поддерживаемые языки и сравнение с альтернативами

Введение
CuneiForm — это система оптического распознавания текста (OCR), созданная для преобразования сканированных изображений, PDF-документов и фотографий в редактируемые текстовые форматы. Программа особенно известна своей высокой точностью при работе с кириллицей и сложными макетами, что делает её востребованной в России и странах СНГ.
Основная задача CuneiForm — максимально точно восстановить структуру документа, сохранив:
• абзацы;
• таблицы;
• шрифтовые особенности;
• межстрочные интервалы;
• разметку страниц.
В отличие от универсальных PDF-редакторов, CuneiForm разрабатывалась как специализированное решение для распознавания текста, что обеспечивает высокую точность и устойчивость при работе с материалами низкого качества — архивными сканами, газетными вырезками и старыми документами.
В этом обзоре рассматриваются интерфейс программы, ключевые функции, точность распознавания, производительность, поддерживаемые форматы, применение в профессиональной среде, а также сравнение CuneiForm с альтернативами OCR.
История развития CuneiForm
CuneiForm имеет богатую историю, уходящую корнями в советские разработки систем автоматического чтения текста. В основе движка лежит научная школа OCR, ориентированная на высокую точность работы с кириллицей и сложной версткой.
Ключевые этапы развития:
• ранние коммерческие версии, ориентированные на корпоративный сектор;
• развитие алгоритмов выделения областей текста, таблиц и графики;
• внедрение модулей анализа структуры документа;
• выпуск свободной версии, доступной пользователям;
• оптимизация под современные операционные системы.
Программа стала одним из первых OCR-решений, способных корректно распознавать документы со смешанной структурой — таблицами, колонтитулами, колонками, декоративными шрифтами. Благодаря этому CuneiForm долгое время была одним из основных OCR-инструментов в библиотечных системах, архивах, государственных учреждениях и издательствах.
Интерфейс и удобство использования
Главное окно и структура интерфейса
Программа имеет классический интерфейс, разделённый на:
• панель управления;
• область предпросмотра;
• панель инструментов;
• зону результатов распознавания;
• элементы навигации по страницам.
Такой подход обеспечивает удобство пользователям, которым необходимо одновременно контролировать исходное изображение и проверять итоговый текст.
Области для загрузки документов
Пользователь может загружать:
• одиночные изображения;
• многостраничные PDF;
• результаты сканирования напрямую через TWAIN;
• набор файлов для пакетной обработки.
CuneiForm автоматически анализирует структуру документа, подсвечивая области текста, графики и таблиц.
Панели настроек распознавания
Настройки позволяют указать:
• язык распознавания;
• приоритет сохранения структуры;
• качество входного изображения;
• параметры корректировки;
• уровень детализации таблиц.
Гибкость настроек делает программу удобной как для новичков, так и для профессионалов, занимающихся регулярной оцифровкой.
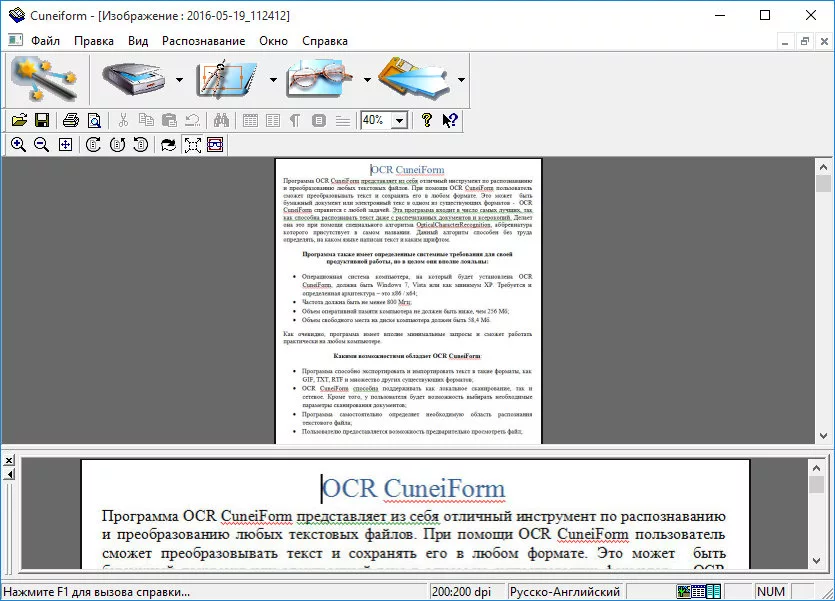
Просмотр оригинала и результата
CuneiForm отображает два окна:
• исходный документ;
• результат распознавания.
Это позволяет сразу сравнить текст и убедиться в точности конверсии. Подсветка распознанных блоков помогает быстро находить ошибки.
Экспорт и сохранение
Программа поддерживает экспорт в:
• DOC;
• RTF;
• TXT;
• HTML;
• внутренние форматы для дальнейшей коррекции.
Структура документа сохраняется максимально точно, включая абзацы, таблицы и оформление.
Основные возможности CuneiForm
OCR-распознавание текста
Основная сила CuneiForm — точность распознавания, особенно при работе с кириллицей. Движок программы анализирует:
• контуры шрифтов;
• интервалы между буквами;
• вероятностные ошибки;
• корректность слов;
• структуру абзацев.
Точность OCR остаётся высокой даже на изображениях среднего качества.
Работа с кириллицей и редкими языками
CuneiForm хорошо распознаёт:
• русский;
• украинский;
• белорусский;
• казахский;
• латиницу;
• распространённые европейские языки.
Алгоритмы программы создавались с учётом особенностей кириллицы, поэтому качество распознавания nередко превосходит универсальные OCR-решения.
Коррекция верстки и сохранение структуры документа
CuneiForm выделяется тем, что восстанавливает верстку:
• колонки;
• таблицы;
• списки;
• фрагменты с разным форматом текста;
• заголовки;
• колонтитулы.
Это особенно важно при оцифровке журналов, газет и книг, где структура критична для понимания текста.
Работа с многостраничными документами
Программа поддерживает:
• загрузку многостраничных PDF;
• пакетное OCR по страницам;
• последовательную навигацию;
• автоматическое определение областей.
Работа с большими документами проходит стабильно и предсказуемо.
Распознавание таблиц
CuneiForm корректно выделяет:
• границы таблиц;
• строки и столбцы;
• вложенные структуры;
• текст внутри ячеек.
Этот функционал используется в бухгалтерии, технической документации и оцифровке отчётов.
Импорт изображений и PDF
Поддерживаемые форматы:
• JPG;
• PNG;
• TIFF;
• BMP;
• PDF (включая многостраничные).
CuneiForm автоматически анализирует качество изображения и применяет коррекцию контрастности при необходимости.
Поддержка сканеров через TWAIN
Программа может работать напрямую со сканером:
• позволяет запускать процесс сканирования;
• задавать параметры качества;
• распознавать сразу после скана;
• сохранять результаты пакетно.
Это делает CuneiForm удобной в офисной среде и для архивных работ.
Дополнительные функции
Обработка пакетов файлов
CuneiForm поддерживает пакетную обработку, что особенно важно для организаций, ежедневно оцифровывающих десятки и сотни страниц. Программа позволяет:
• добавлять в очередь множество файлов;
• распознавать их в автоматическом режиме;
• сохранять результаты в выбранном формате;
• применять единые настройки ко всей партии.
Такой подход облегчает массовую оцифровку архивов, книг, отчётов и деловых документов.
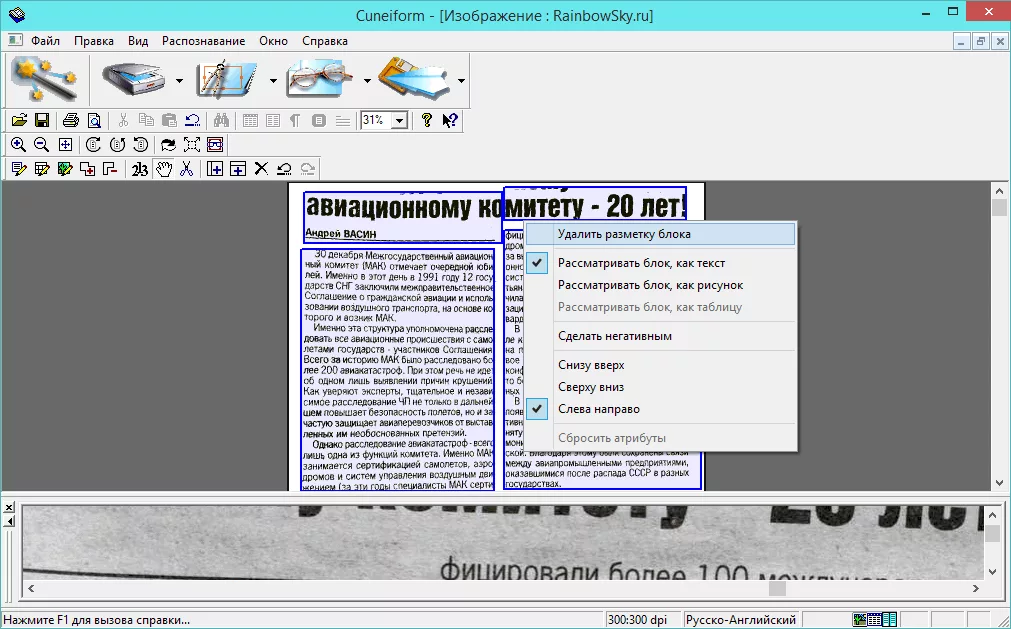
Ручная разметка областей
Хотя CuneiForm хорошо справляется с автоматическим определением зон, она также позволяет пользователю вручную отметить:
• текстовые блоки;
• заголовки;
• таблицы;
• изображения;
• многоуровневые элементы.
Это важно, когда исходное изображение содержит:
• смещения;
• дефекты бумаги;
• шумы;
• сложную верстку.
Ручная разметка повышает точность итогового распознавания.
Печать распознанного текста
После распознавания пользователь может:
• отправить результат на печать;
• сохранить документ в виде макета;
• вывезти текст в читабельном виде.
Это удобно для организаций, печатающих отчёты или архивные материалы после OCR.
Настройки посткоррекции
Для повышения качества текста имеются функции:
• автоматическая проверка правописания;
• корректировка блоков;
• настройка выравнивания;
• выбор стилей оформления;
• удаление лишних пробелов и элементов.
Посткоррекция помогает получить чистый результат без ручной доработки.
Обработка низкокачественных изображений
CuneiForm включает алгоритмы для улучшения качества:
• увеличение контрастности;
• фильтрация шумов;
• коррекция наклона страницы;
• устранение искажений;
• обработка размытых участков.
Это делает программу пригодной для оцифровки архивных материалов и старых сканов.
Работа со шрифтами и нестандартными символами
Программа корректно обрабатывает:
• нестандартные кириллические гарнитуры;
• декоративные шрифты;
• старые журнальные шрифты;
• редкие символы и лигатуры.
Этот функционал востребован при оцифровке книг, журналов и исторических материалов.
Производительность и стабильность
Скорость распознавания
CuneiForm демонстрирует высокую скорость OCR даже на средних ПК. Скорость зависит от сложности структуры, но в большинстве случаев распознавание занимает 2–10 секунд на страницу.
Качество работы с разными типами изображений
Программа уверенно распознаёт:
• текст на белом фоне;
• материалы со сложной версткой;
• газетные вырезки;
• низкоконтрастные изображения;
• документы с потертостями.
Даже на некачественных сканах получается приемлемый результат.
Требовательность к оборудованию
CuneiForm не относится к ресурсоёмким OCR-системам. Её можно использовать:
• на офисных ПК 2010–2015 годов;
• на ноутбуках бюджетного уровня;
• на системах с 2–4 ГБ ОЗУ.
Поведение на слабых компьютерах
Даже на слабых системах программа:
• запускается быстро;
• распознаёт стабильно;
• редко вызывает зависания.
Сравнение скорости с альтернативами
• CuneiForm быстрее, чем Tesseract без оптимизации.
• Медленнее FineReader при максимальной детализации, но в повседневных задачах разница минимальна.
• Быстрее Acrobat OCR на старых ПК.
В целом производительность программы подходит для массовой оцифровки и потоковой обработки документов.
Поддержка платформ и совместимость
Совместимые версии Windows
CuneiForm работает на большинстве актуальных версий Windows, включая старые редакции.
Совместимость с форматами изображений
Программа поддерживает:
• TIFF;
• JPEG;
• PNG;
• BMP;
• многостраничные TIFF-файлы.
Корректность экспорта в DOC, TXT, HTML
Экспорт в текстовые форматы отличается высокой точностью:
• DOC сохраняет структуру и оформление;
• TXT подходит для чистого текста;
• HTML сохраняет таблицы, выделения и верстку.
Работа с PDF
Программа поддерживает импорт PDF:
• с текстовым слоем;
• с растровыми изображениями;
• с многостраничными документами.
Распознавание PDF происходит быстро и точно, что делает программу полезной для архивов и офисов.
Системные требования
Минимальные:
• процессор: 1 ГГц;
• 1 ГБ оперативной памяти;
• около 300 МБ свободного места;
• совместимая версия Windows.
Рекомендуемые:
• процессор: двухъядерный;
• 4 ГБ ОЗУ;
• SSD-диск для ускоренной загрузки файлов.
Особенности работы на старых компьютерах
CuneiForm хорошо работает:
• на старых офисных ПК;
• на слабых ноутбуках;
• на системах с ограниченными ресурсами.
Это делает программу привлекательной для организаций с устаревшим оборудованием.
CuneiForm в профессиональной среде
Офисы и документооборот
CuneiForm отлично подходит для:
• распознавания служебных документов;
• подготовки отчётов;
• обработки бумажной корреспонденции;
• перевода документов в электронный вид.
Оцифровка архивов
Библиотеки и архивы используют CuneiForm из-за её устойчивости к низкому качеству источников.
Книги и журналы
Программа хорошо справляется:
• с колонками;
• сложной разметкой;
• декоративными шрифтами.
Техническая документация
CuneiForm подходит для распознавания:
• схем;
• таблиц;
• инструкций;
• чертежей.
Учебные заведения
Подходит для создания электронных библиотек и методических материалов.
Библиотечные системы
Используется для создания электронных фондов и каталогов благодаря стабильности и точности.
Плюсы и минусы CuneiForm
Плюсы:
• высокая точность распознавания кириллицы;
• корректная работа со сложной версткой (колонки, таблицы, списки);
• поддержка архивных и низкокачественных изображений;
• простота интерфейса;
• поддержка TWAIN-сканеров;
• стабильная работа на слабых компьютерах;
• экспорт в DOC, RTF, TXT, HTML;
• ручная разметка областей;
• пакетная обработка файлов;
• корректное распознавание редких шрифтов и символов.
Минусы:
• интерфейс устаревшего вида;
• меньше возможностей настройки OCR, чем в профессиональных решениях;
• отсутствие современного движка постобработки;
• не поддерживаются некоторые редкие языки;
• распознавание декоративных шрифтов иногда требует ручной корректировки;
• нет облачных функций;
• отсутствуют инструменты редактирования PDF внутри программы.
Сравнение CuneiForm с аналогами
PDF Commander]
PDF Commander ориентирован на редактирование PDF и базовое OCR внутри программы. Однако его распознавание менее точное, особенно на сложных макетах. CuneiForm выигрывает в качестве OCR, но PDF Commander более универсален.
ABBYY FineReader]
FineReader — лидер рынка OCR. Он точнее, быстрее, современнее, поддерживает больше языков и имеет продвинутые алгоритмы восстановления структуры. Но он значительно тяжелее, дороже и требовательнее к оборудованию. CuneiForm — более лёгкая и бесплатная альтернатива для простых и средних задач.
Tesseract OCR]
Tesseract — мощный движок, но требует настройки и не всегда корректно работает с версткой. CuneiForm удобнее для непрофессионалов и работает точнее на кириллице без сложной конфигурации.
Adobe Acrobat OCR]
Acrobat предлагает OCR внутри PDF, но его точность по кириллице уступает CuneiForm на сложных документах. Зато Acrobat удобнее при работе с PDF.
OmniPage]
OmniPage — профессиональная система, превосходящая CuneiForm по техническим возможностям. Но она сложна и дорога. CuneiForm остаётся более доступным выбором для организаций с ограниченным бюджетом.
Общий вывод по сравнению]
CuneiForm занимает нишу между простыми бесплатными решениями и профессиональными комплексами. Она превосходит многие бесплатные OCR-системы по качеству работы с кириллицей, но уступает профессиональным продуктам по скорости и функциональности.
FAQ
1. Поддерживает ли CuneiForm кириллицу?
Да, и она распознаётся особенно качественно.
2. Можно ли распознавать PDF?
Да, программа поддерживает импорт PDF с растровыми страницами.
3. Есть ли распознавание таблиц?
Да, таблицы выделяются автоматически и сохраняют структуру.
4. Поддерживает ли программа сканеры?
Да, через TWAIN.
5. Как экспортировать результат распознавания?
В DOC, RTF, TXT, HTML.
6. Можно ли распознавать фотографии с телефона?
Да, если изображение достаточно чёткое.
7. Обрабатывает ли программа низкокачественные сканы?
Да, есть алгоритмы коррекции контрастности и шумов.
8. Можно ли распознавать многостраничные документы?
Да, это одна из ключевых возможностей.
9. Есть ли пакетная обработка?
Да, можно распознавать десятки файлов за один цикл.
10. Сохраняется ли структура документа?
Да, программа восстанавливает абзацы, таблицы, списки и другие элементы.
11. Есть ли автоматическая проверка орфографии?
Да, встроенные инструменты посткоррекции помогают исправлять ошибки.
12. Нужно ли мощное оборудование?
Нет, CuneiForm работает стабильно даже на старых ПК.
13. Можно ли использовать в библиотеках и архивах?
Да, это одно из основных направлений применения.
14. Есть ли поддержка редких языков?
Поддерживаются основные европейские языки, но нет широкого набора мировых языков.
15. Можно ли использовать программу для обработки журналов?
Да, особенно благодаря корректной работе с колонками и версткой.
Отзывы пользователей
Чаще всего отмечают:
• высокую точность на кириллице;
• удобство ручной разметки;
• стабильность на старых системах;
• хорошее восстановление структуры документа;
• пригодность для архивной работы.
Наиболее распространённые замечания:
• устаревший интерфейс;
• нехватка современных функций OCR;
• необходимость ручной доредактуры сложных страниц;
• ограниченный набор языков;
• отсутствие продвинутой постобработки.
В целом пользователи считают CuneiForm отличным выбором для задач, связанных с кириллическими текстами и оцифровкой архивных документов.
Итоговое заключение
CuneiForm — мощная и точная OCR-система, ориентированная на распознавание сложных документов с кириллицей. Она сочетает высокую точность, стабильность и низкие системные требования, что делает её востребованной в архивной, образовательной и офисной среде.
Кому подходит:
• архивам и библиотекам;
• офисам с бумажным документооборотом;
• пользователям, которым важно качество распознавания кириллицы;
• организациям с ограниченным бюджетом;
• учебным заведениям и научным организациям.
Кому не подойдёт:
• тем, кому нужна максимальная точность уровня FineReader;
• пользователям, работающим с редкими мировыми языками;
• тем, кто предпочитает современные интерфейсы;
• тем, кому нужен полноценный PDF-редактор.
Сильные стороны:
• точность;
• устойчивость к низкому качеству источника;
• сохранение структуры;
• лёгкость освоения;
• работа на слабых ПК.
Ограничения:
• ограниченный набор языков;
• устаревший интерфейс;
• меньше возможностей постобработки, чем у профессиональных решений.
Общий вывод
CuneiForm остаётся одним из наиболее точных бесплатных OCR-решений для кириллицы. В 2025 году программа остаётся актуальной для организаций и пользователей, которым нужна стабильная и проверенная временем система распознавания без высокой нагрузки на оборудование.
![Jinn'sLiveUSB 11.5 - флешка с Windows 7, 8.1, 10 и 11 [Ru/En]](/uploads/posts/2023-12/26c.jpg)



